
A selecção adequada de tamanhos de máquinas virtuais (VMs) no Azure constitui um dos aspectos centrais de qualquer arquitectura de computação na cloud. Independentemente da maturidade técnica das organizações, a escolha correcta do tipo e tamanho de VM influencia directamente o desempenho, a escalabilidade, os custos operacionais e o cumprimento dos acordos de nível de serviço (SLAs). Ao longo dos últimos anos, a plataforma Azure tem aumentado a diversidade e especialização das suas famílias de máquinas virtuais, permitindo uma adaptação quase cirúrgica às necessidades de cada workload. Todavia, esta abundância de opções torna o processo de selecção mais complexo e, simultaneamente, mais importante.
Este artigo apresenta uma análise sistemática, concisa e profundamente técnica sobre como seleccionar tamanhos de VM no Azure de forma profissional, abordando as características de cada família, o processo decisório baseado em métricas reais e os princípios fundamentais para optimização de desempenho em ambientes produtivos.
1- Entender o Papel das Famílias de VM
As famílias de VM no Azure são agrupadas de acordo com o tipo de recurso predominante que oferecem: CPU, memória, capacidade de armazenamento, GPU ou equilíbrio entre estes elementos. Cada família foi concebida para um conjunto específico de cargas de trabalho, e ignorar esta associação implica quase sempre desperdício ou sub‑desempenho.
1.1- Família de Uso Geral
As famílias D, Dv5, Dasv5 e equivalentes representam o equilíbrio. São máquinas virtuais adequadas a servidores Web, aplicações empresariais tradicionais, camadas de aplicação e workloads cuja relação CPU/memória se mantém estável.
Estas séries caracterizam-se por:
- Bom compromisso entre preço e desempenho
- Latência reduzida para operações de rede
- Versatilidade para ambientes heterogéneos
São, em regra, a escolha incial mais segura para maioria das aplicações.
1.2- Famílias Otimizadas para Memória
As séries E e M destinam‑se a workloads intensivos em memória, incluindo bases de dados relacionais, operações analíticas e cargas “in‑memory”. Estas máquinas disponibilizam grandes quantidades de RAM por vCPU, com particular foco em estabilidade sob cargas prolongadas.
Estas séries são indispensáveis para:
- Servidores SQL Server, Oracle ou PostgreSQL
- SAP HANA
- Ferramentas de análise avançada
- Caches distribuídas em larga escala
1.3- Famílias Otimizadas para CPU
A série F é projectada para cargas computacionalmente pesadas, como microserviços de alta performance, processamento intensivo de API, gateways de tráfego elevado ou workloads que exijam elevada densidade de operações por segundo.
1.4- Famílias Otimizadas para Armazenamento
A série L é optimizada para throughput e latência reduzida ao nível do disco. É usada tipicamente para bases de dados NoSQL, motores distribuídos de armazenamento, ou para workloads com forte dependência de IOPS.
1.5- Famílias com GPU
As séries N são centradas em capacidades gráficas e paralelização massiva. São imprescindíveis para workloads modernos de aprendizagem automática, renderização, simulações e treino de modelos de IA.
2- A Ciência da Escolha: Como Seleccionar o Tamanho Adequado
A selecção adequada do tamanho da VM não é um exercício meramente empírico; trata‑se de um processo técnico que deve ser guiado por métricas, padrões de utilização e objectivos de negócio.
2.1- Identificação do Tipo de Workload
Um dos primeiros passos passa por identificar se o workload é:
- CPU‑bound (limitado pela capacidade de processamento)
- Memory‑bound (limitado pela RAM disponível)
- I/O‑bound (dependente de operação em disco)
- Network‑bound (dependente de largura de banda)
- GPU‑bound (requer aceleração gráfica)
A partir desta classificação o âmbito de escolha reduz‑se substancialmente, orientando o arquitecto para famílias adequadas às necessidades reais.
2.2- Dependências de SLA e Requisitos Empresariais
Máquinas virtuais que suportam discos Premium SSD v2 ou Ultra Disk, ou que integram suporte para Accelerated Networking, tendem a apresentar maior estabilidade e previsibilidade de desempenho. Isto é essencial para workloads críticos e sujeitos a contratos rígidos de disponibilidade.
2.3- Disponibilidade Regional e Quotas
Nem todos os tamanhos estão disponíveis em todas as regiões. Além disso, subscrições com limites de vCPUs, GPUs ou séries específicas podem condicionar a escolha inicial. O planeamento deve começar com a validação da disponibilidade no local onde o workload será implementado.
2.4- Custo versus Desempenho
Uma das armadilhas comuns reside na suposição de que “mais CPU significa melhor desempenho”, o que raramente é verdade. Máquinas com mais vCPUs podem apresentar menor desempenho por núcleo, ou resultar em custos desnecessários. A série v5 e subsequentes apresenta, em geral, melhor relação custo‑performance do que famílias mais antigas.
3- Estratégias de Optimização de Desempenho
Optimizar uma VM significa minimizar latências, garantir estabilidade e aumentar a eficiência de consumo de recursos.
3.1- Utilização de Discos Premium SSD v2 ou Ultra Disk
Workloads I/O‑bound beneficiam significativamente destas opções, que oferecem:
- IOPS consistentes
- Menor latência
- Throughput superior
- Maior previsibilidade em cargas críticas
3.2- Activação do Accelerated Networking
Sempre que o tamanho da VM o permita, esta funcionalidade deve ser activada. A aceleração de rede melhora a largura de banda, reduz a latência e reduz a carga de CPU associada ao processamento de pacotes.
3.3- Escalar Horizontalmente Sempre que Possível
A escalabilidade horizontal, através de Virtual Machine Scale Sets, oferece maior resiliência do que a escalabilidade vertical. Em vez de aumentar indefinidamente o tamanho da VM, distribuir carga por múltiplas instâncias reduz pontos únicos de falha e melhora o balanceamento de recursos.
3.4- Dimensionamento com Base em Métricas Reais
Antes de fixar um tamanho definitivo, recomenda‑se:
- Implementar uma VM de tamanho intermédio
- Monitorizar métricas reais CPU, memória, throughput, latência, utilização de disco
- Reavaliar o dimensionamento com base em dados observados
- Ajustar horizontal ou verticalmente conforme necessário
4- Erros Comuns e Como Evitá‑los
A experiência prática demonstra que alguns erros são recorrentes:
- Sobre‑dimensionamento: máquinas demasiado grandes levam a custos elevados e desperdício.
- Sub‑dimensionamento: máquinas pequenas saturam mais rápido, causando degradação do serviço.
- Uso de discos Standard em produção: altamente desaconselhado para workloads críticos.
- Dependência exclusiva de escalabilidade vertical: limita redundância e resiliência.
- Escolha de séries antigas (como DS2_v2): séries modernas são quase sempre mais rápidas e eficientes.
- Ignorar latência de rede e throughput: escolher a VM sem considerar necessidades de rede compromete o desempenho.
5- Guia Prático de Selecção
A tabela seguinte serve como orientação inicial:
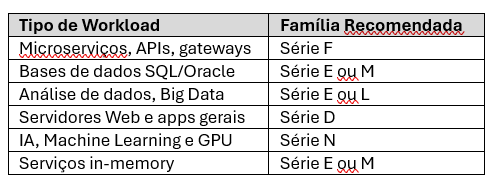
Concluindo a escolha do tamanho ideal de VM no Azure é tanto um exercício técnico quanto uma decisão arquitectural. Exige compreender a natureza do workload, conhecer profundamente as famílias disponíveis e interpretar métricas operacionais com rigor. Como recomendação prática: optar por séries modernas (v5/v6), privilegiar escalabilidade horizontal, activar aceleradores de rede e recorrer a discos de elevado desempenho.
Ao dominar estes princípios, qualquer arquitecto consegue construir infraestruturas compute robustas, escaláveis e economicamente eficientes, preparadas para ambientes empresariais de elevada exigência.
Deixe o seu comentário e até ao próximo artigo!